An AI instructor for surgical training — built on data from Mass General.
Twelve patients. One surgical procedure. A team of four. The problem: surgical residents need a senior doctor in the room to learn artery identification, and senior doctors are the most expensive resource in a hospital. The hypothesis: an ML model can stand in. The result: 71% IoU on segmentation, validated by 4 doctors.
The senior doctor problem.

The robotic surgery setup our model runs against. Artery identification during procedures like this is the skill our AI instructor is built to teach.
Surgical residents learn complex procedures the same way they have for decades — by standing next to a senior surgeon, getting corrected in real time, gradually being trusted with more of the operation. The bottleneck is obvious: the senior surgeon has to be there, every time. For artery identification in particular — a foundational skill in thoracic surgery — this means one of the most expensive resources in a hospital is committed to repetitive teaching.
The team I worked with — Kishlay Kumar, Pratyay Prakhar, Syed Abdul Khader, and myself — asked a sharper question: can a model identify arteries in surgical video accurately enough that the senior doctor doesn't need to be physically present for every training session?
If the answer is yes, you don't replace the surgeon. You free them up for the cases that actually need their judgement. Hospitals get more training throughput. Residents get more practice. Patients eventually benefit from better-trained surgeons.
One sentence, four months of work.
The reliance on a doctor's intervention during a resident's training can be eliminated, while maintaining a high level of accuracy in real-time artery identification.
That sentence had to do a lot of work. "Eliminated" was probably too strong — "reduced" was more honest. "High level of accuracy" needed a number. "Real-time" needed a latency target. The product question was inseparable from the ML question.
The hypothesis was validated by a panel of four doctors from SCOPE — a thoracic surgery and surgical education group — before we wrote a line of code. They confirmed the educational use case, and crucially, they told us what "accurate enough" would mean to them.
How we ran it.
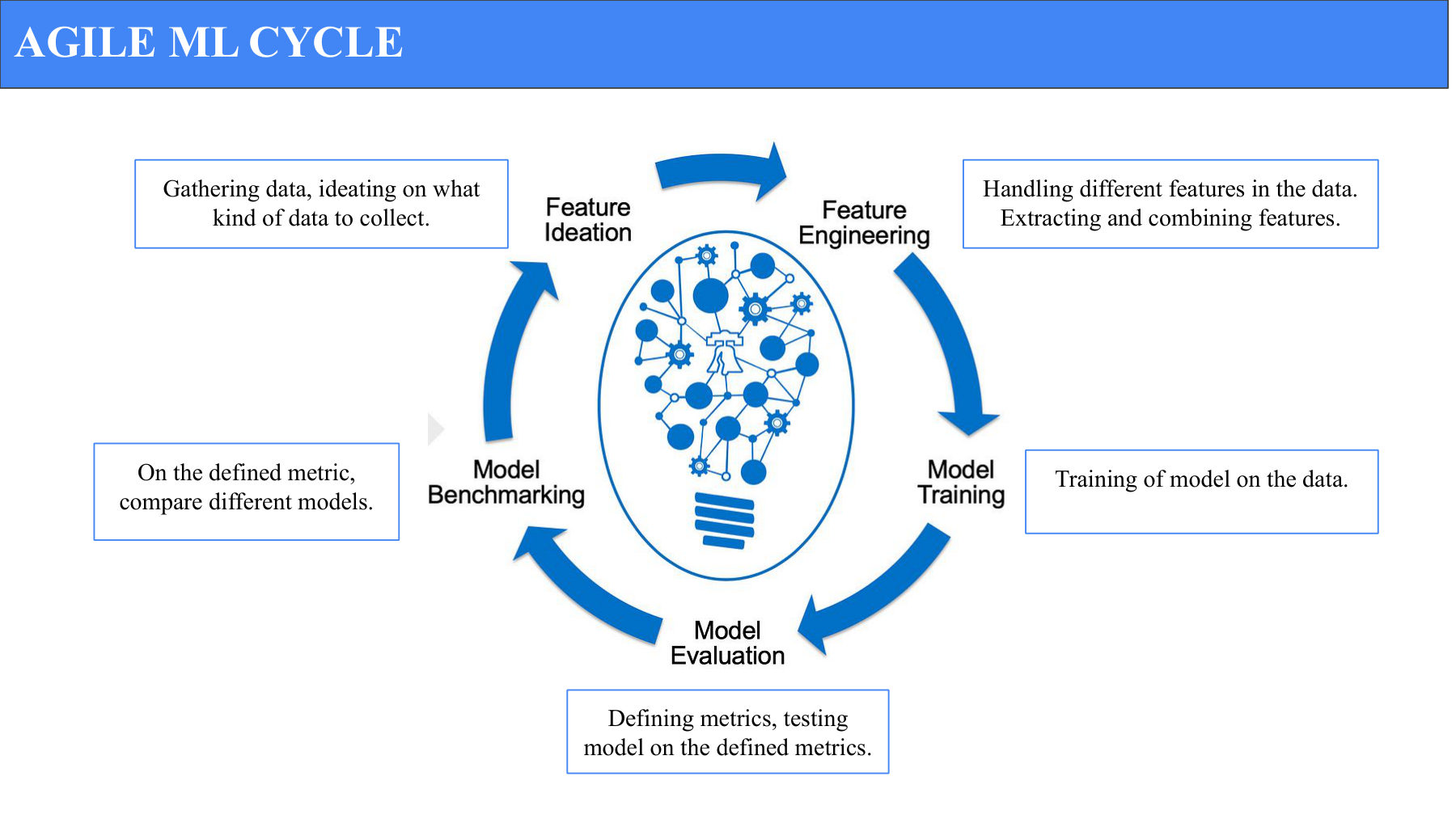
The five-stage Agile ML loop we ran in two-week sprints. Each cycle produced a comparable model result — no sprint ran longer than two weeks without a measurable evaluation.
ML projects fail when they're treated as one-shot model builds. We ran this as an iterative loop — five stages, every two weeks:
- Gather data. Decide what to collect, collect it, label it.
- Feature engineering. Extract and combine features from the raw video frames.
- Train. Run candidate models on the prepared data.
- Define and test metrics. Evaluate on a held-out set against the defined metric.
- Compare models. Benchmark candidates against each other; pick what to push forward.
Each sprint compressed this loop. The cycles meant we were never more than two weeks from knowing whether the current direction was working.
The hardest part wasn't the model. It was the labels.
The first wall we hit: there are no public surgical video datasets labelled with anatomy like arteries and veins. If we wanted segmentation ground truth, we had to make it.
We worked with data from twelve patients who underwent Thoracic Left Lower Lobe surgery — a procedure where artery identification is critical. Each surgery video runs about an hour and a half. We didn't need every minute. We pulled 1–5 minute snippets where the arteries were exposed, then annotated frame-by-frame.
The annotation strategy
- Initial labelling by medical students. Pragmatic — they're cheaper than surgeons, and they're trained well enough to identify arteries with high agreement.
- Senior-doctor review on a sample. We had the SCOPE doctors validate a subset of the annotations to ensure inter-rater agreement.
- Frame-by-frame masks. Polygon segmentation around the visible artery in each frame.
From baseline to state-of-the-art.
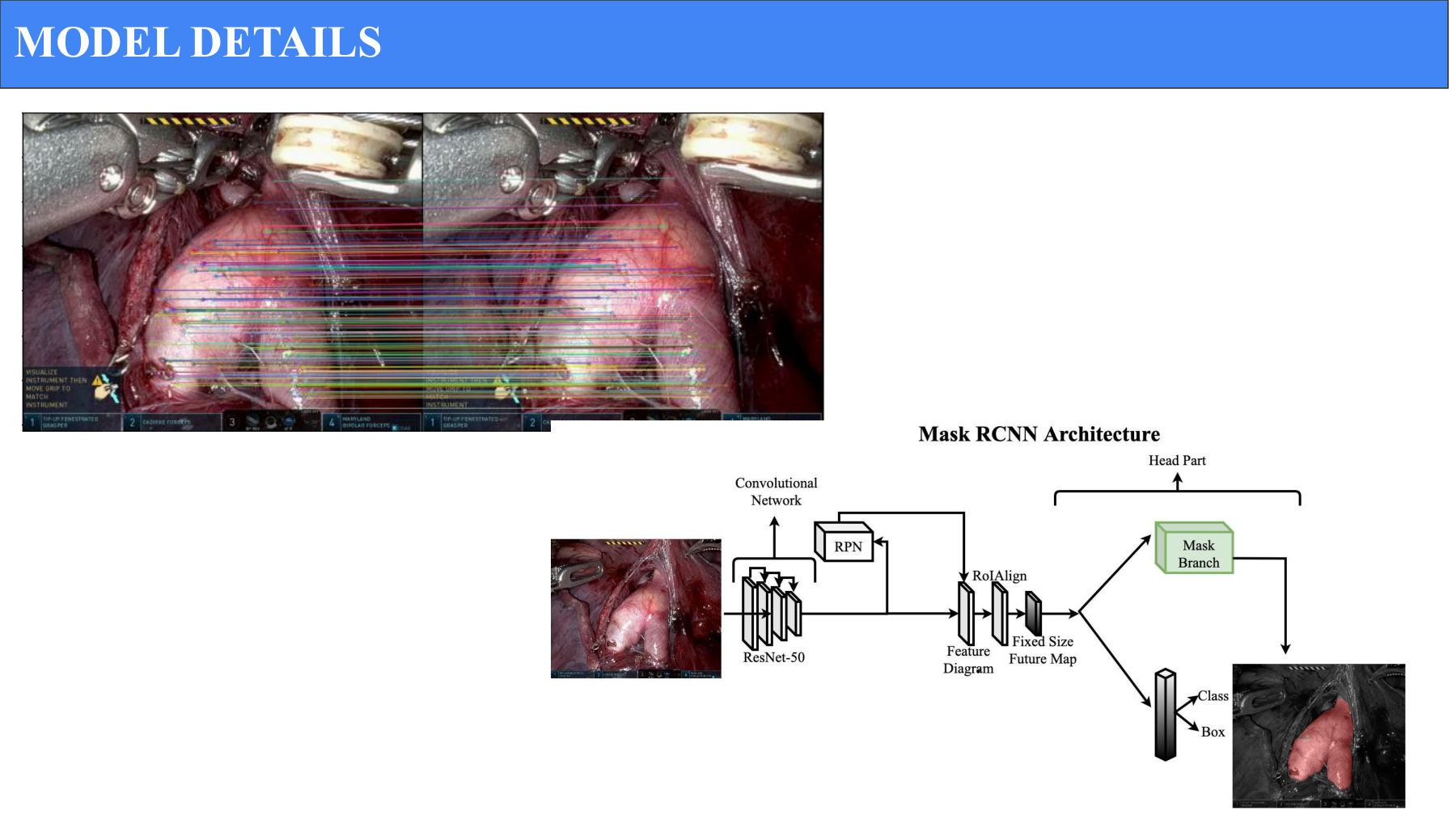
SIFT feature matching on actual surgical video. Colored lines connect matched feature points across consecutive frames — this was our classical baseline at 7.1% IoU before we moved to learned models.
Baseline — SIFT tracking
We started with a classical computer vision approach. SIFT (Scale-Invariant Feature Transform) extracts distinctive features from each frame and matches them across frames to track the artery. It's an honest baseline — fast to set up, transparent, no learned parameters.
First learned model — Mask-RCNN
We trained Mask-RCNN, an off-the-shelf instance segmentation model, on 80% of our data with 20% held out for validation. We initialised with a pre-trained ResNet50 backbone (ImageNet weights) rather than training from scratch — the right call for a domain where labelled data is the scarcest resource.
Improving Mask-RCNN — augmentation and tuning
The first Mask-RCNN training jumped to 22.6% IoU on the 4-patient subset and ~43% on the full set without augmentation. Heavy data augmentation (rotation, brightness, contrast, perspective shifts) pushed us to 66.59% IoU — a significant jump that vindicated the augmentation strategy.
Memory-aware tracking — X-Mem
Mask-RCNN treats each frame independently. But surgical video has strong temporal continuity — the artery in frame N is almost certainly very close to the artery in frame N-1. X-Mem is a model that remembers past frames in memory and uses that context to improve tracking. Pre-trained X-Mem hit ~66% IoU; X-Mem fine-tuned on our data reached 71% IoU (prospective — final results were still being confirmed at the time of writing).
The metric that actually mattered.
We picked Intersection over Union (IoU) — the area of overlap between predicted artery mask and ground-truth mask divided by the area of their union — as the headline metric. Three reasons:
- It penalises both false positives and false negatives. A model that over-segments (claims too much is artery) and one that under-segments (misses the artery) both score worse. Accuracy alone would have been gameable.
- It's well-understood by the ML community. Easy to compare against published surgical segmentation work.
- It's interpretable to doctors. "70% overlap with what an expert would draw" is a sentence a surgeon can react to.
We also measured generalisation IoU — how well a model trained on patients 1–10 performed on patients 11–12. That number tells you whether you have a model or a memoriser.
The progression that mattered.
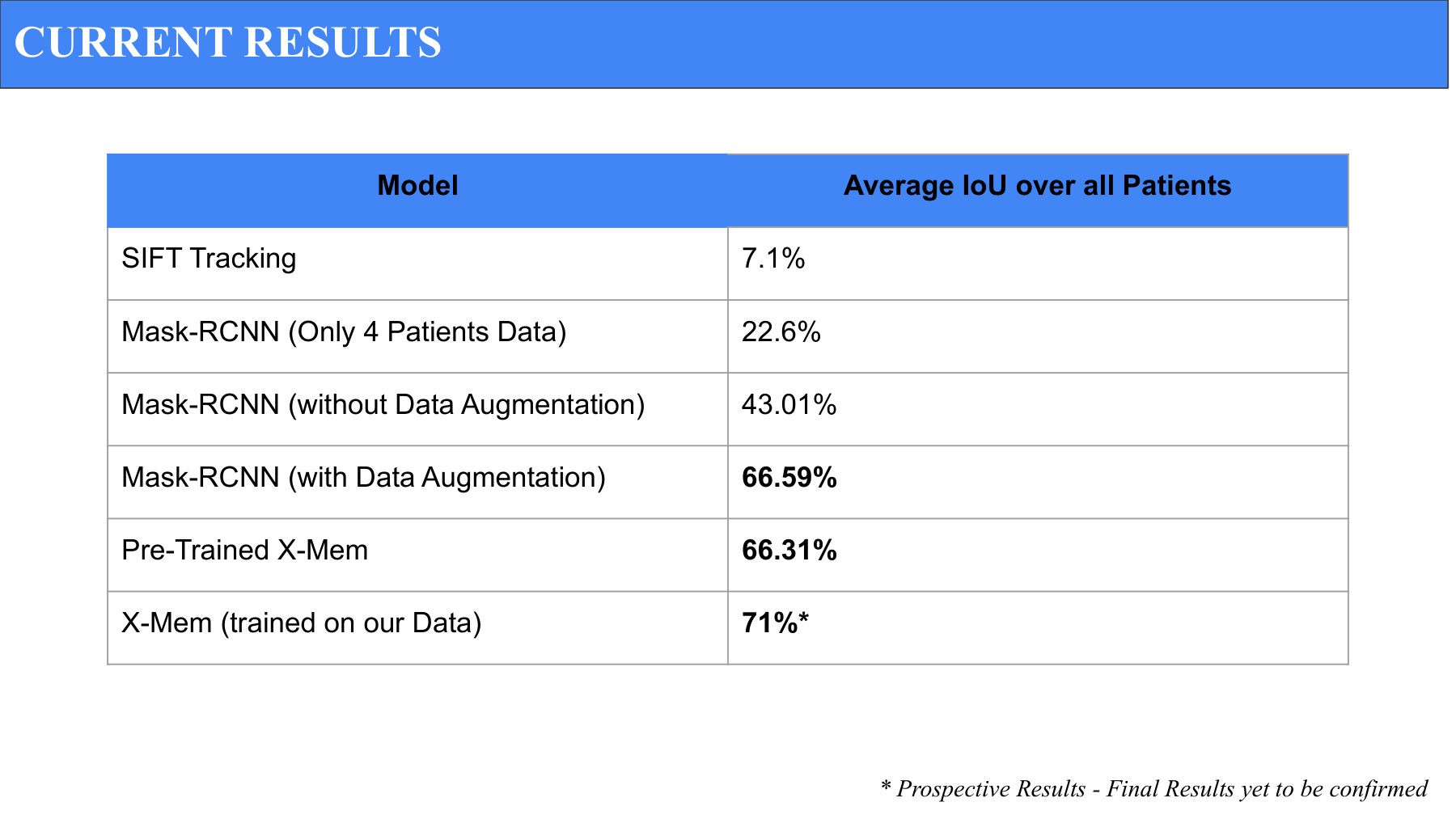
IoU progression across all models. Each row is a deliberate architectural decision — the 23-point jump from no augmentation to augmented Mask-RCNN alone validated our data strategy.
- SIFT tracking: 7.1% IoU. Confirmed that classical CV alone wasn't enough.
- Mask-RCNN (4 patients): 22.6% IoU. Small data, predictable result.
- Mask-RCNN (no augmentation): 43.01% IoU. More data, no tricks.
- Mask-RCNN (with augmentation): 66.59% IoU. Augmentation alone gave us a 23-point lift.
- Pre-trained X-Mem: 66.31% IoU. Memory architecture matched augmented Mask-RCNN out of the box.
- X-Mem fine-tuned on our data: 71% IoU (prospective). The combination of memory-aware tracking and domain-specific fine-tuning was the winning recipe.
Visual demonstration
Our demo overlays three colours on the surgical video:
- Green: Correct prediction — model agreed with ground truth.
- Red: Wrongly predicted — model claimed artery where there wasn't one.
- Blue: Ground truth missed — actual artery the model failed to predict.
A surgeon watching this can immediately see where the model is reliable and where it isn't — which matters far more than a single aggregate IoU number.
Four people, two-week sprints.

The SCRUM structure we ran: Sprint Planning every other Wednesday, daily standups, Retrospective every other Thursday, Sprint Review every other Tuesday. Jira for backlog, Confluence for docs.
This wasn't a model in a notebook. It was a team project with timelines, dependencies, and a hard deadline. We ran a SCRUM framework with extremely agile 2-week sprints:
- Daily standups. 10 minutes. Blockers, plans, ask for help.
- Sprint planning every other Wednesday. Pull from a refined backlog into the sprint.
- Sprint review every other Tuesday. Demo to the team and our doctor advisors.
- Retro every other Thursday. What worked, what didn't, what to change.
User stories with empathy
We wrote our user stories in the standard "As a [role], I want [outcome], so that [reason]" format — but the trick was anchoring them to actual surgical residents we'd interviewed. "As a second-year resident, I want real-time feedback on artery identification, so that I don't have to interrupt my attending surgeon during simulated runs." That sentence directed three sprints of work.
Estimating with Plan IT Poker
We used planning poker to estimate user stories — every team member silently picks a complexity number, then we reveal and discuss. The discussions on big disagreements were where the team learned the most about each other's view of the work.
What I'd build into v2.
The model is good enough to be useful. It's not good enough to be left unsupervised. The next phase of work — much of which was ongoing when I left the project — included:
- Generalisation across procedures. We trained on one specific surgery (Thoracic Left Lower Lobe). Expansion requires data from related procedures and careful evaluation of whether features transfer.
- Real-time inference optimisation. For training scenarios, the model needs to run at video framerate. X-Mem at high IoU is great; X-Mem at high IoU and 30fps is what ships.
- Confidence calibration. A 70% IoU mean hides a lot of variance. The product should explicitly surface low-confidence frames so the resident knows when to ask a senior.
- A teaching interface, not just an inference layer. The model is the backend. The frontend has to feel like a tutor — explaining what it sees, why, and what the resident missed.
What I took away
The technical lesson: data augmentation and memory-aware models are huge unlocks in domains where labelled data is scarce. The product lesson: working with doctors made every product question sharper. They didn't care about IoU as a number — they cared about whether a resident could trust the model. The right product is built one trust unit at a time.